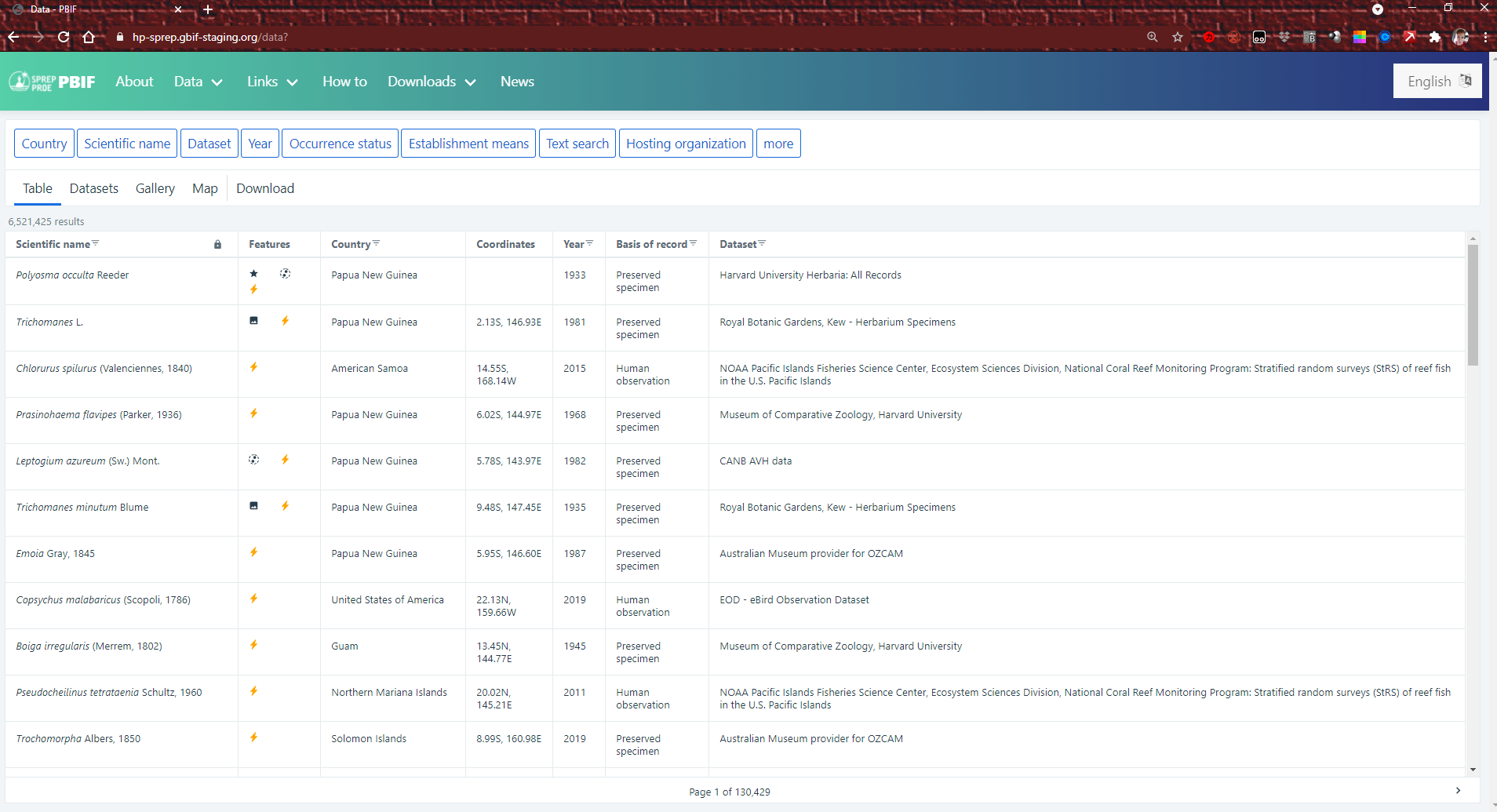
How do I use PBIF portal to find data?
The site pbif.sprep.org contains over six million records of species, specimens, observations, and samples for the Pacific.
Each record will have information about how to download and cite the data. Try exploring the site!
Start by searching from the homepage or clicking on “Data” in the top panel. You can look for
occurrence data, search by species, look for whole datasets, and more.
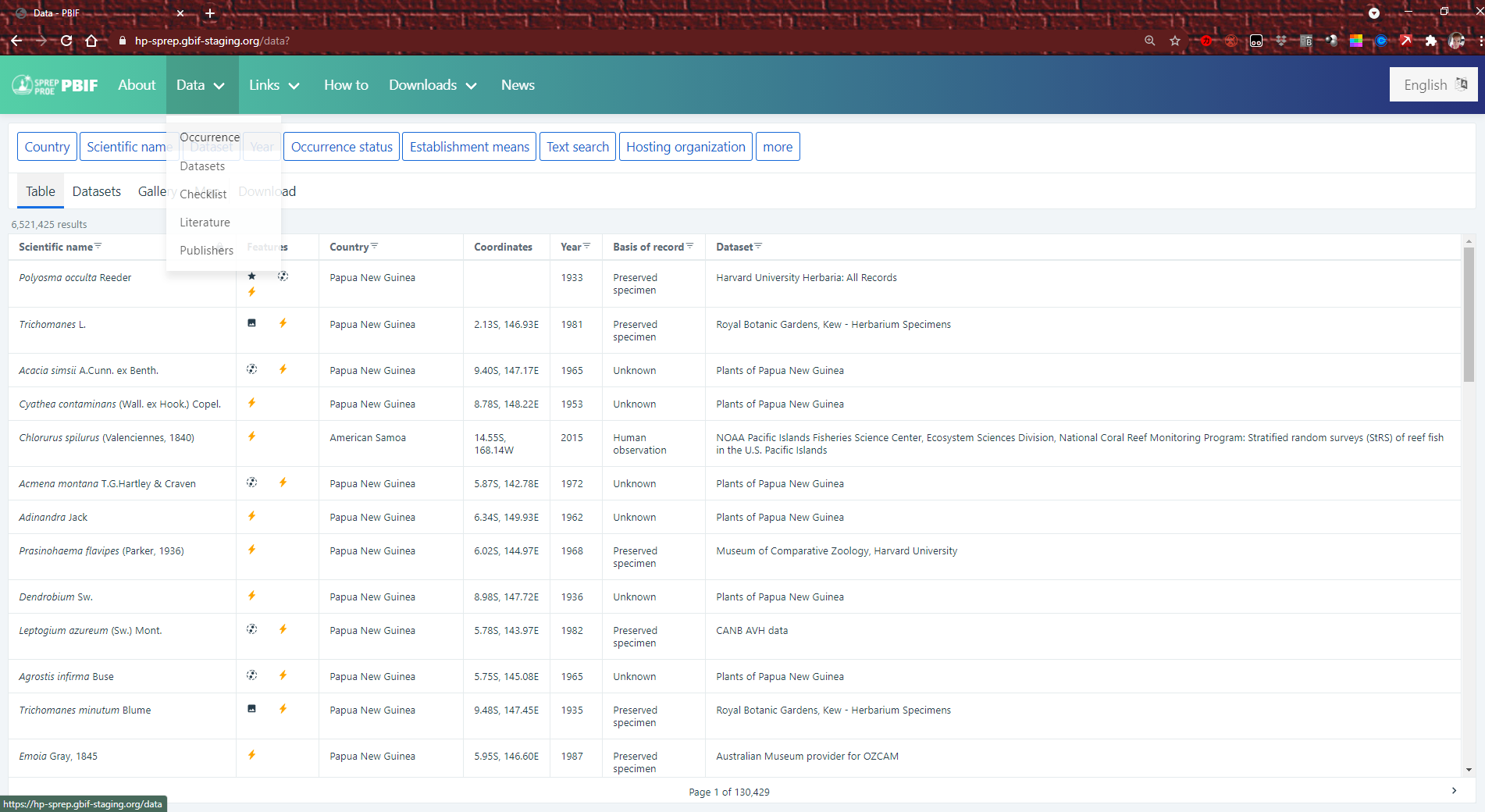
You can search for whole datasets using keywords. In this example, we’re looking for datasets with titles that include “invasive”. (Note that you might not find all the data available about invasive species this way. You will only find datasets that have been labelled using that exact word.)
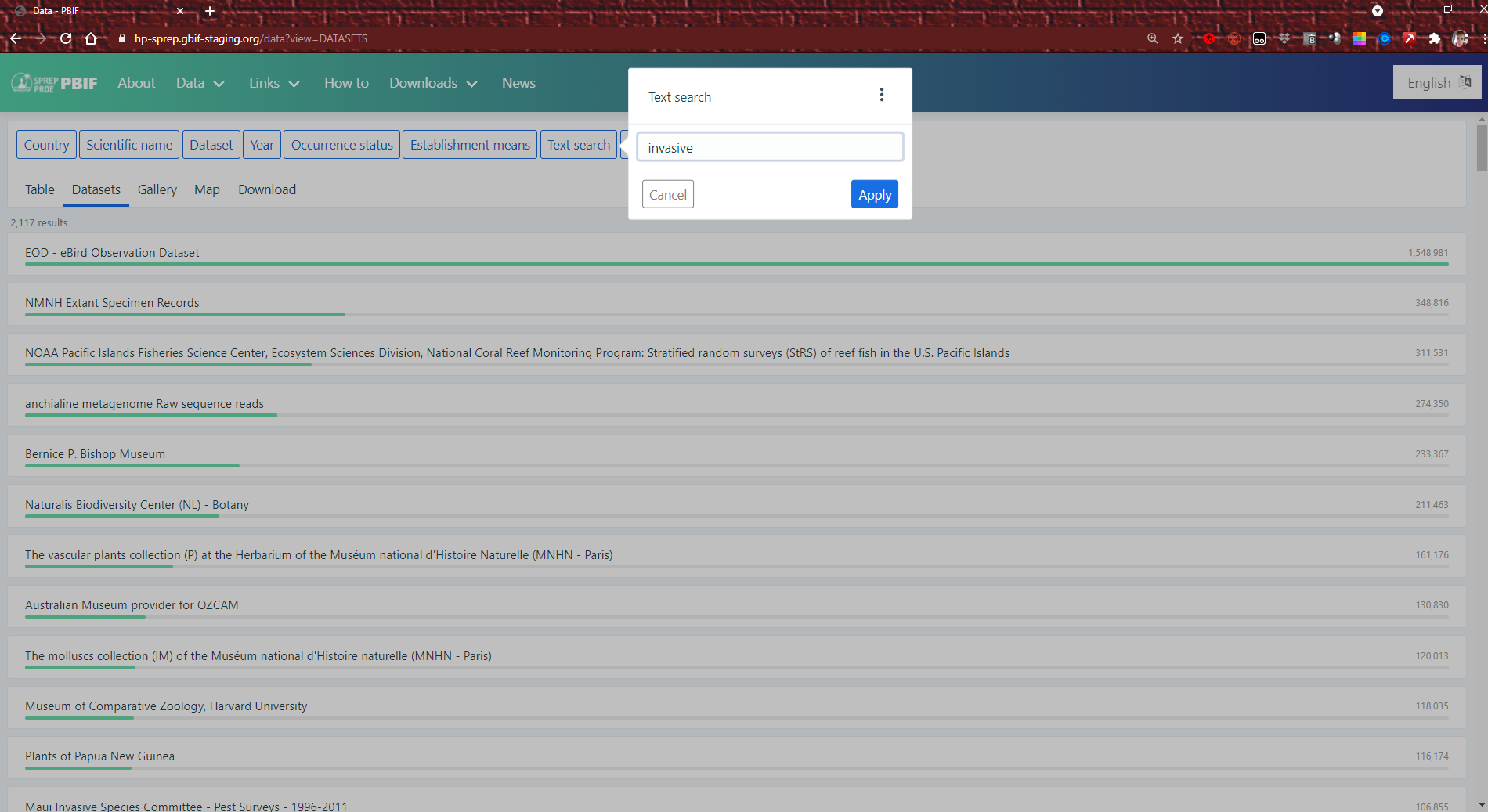
You can search for datasets by region, called “Publishing country or area” in the left panel. You can search for multiple countries at a time and combine with other filters: each checked box will be included in your search.
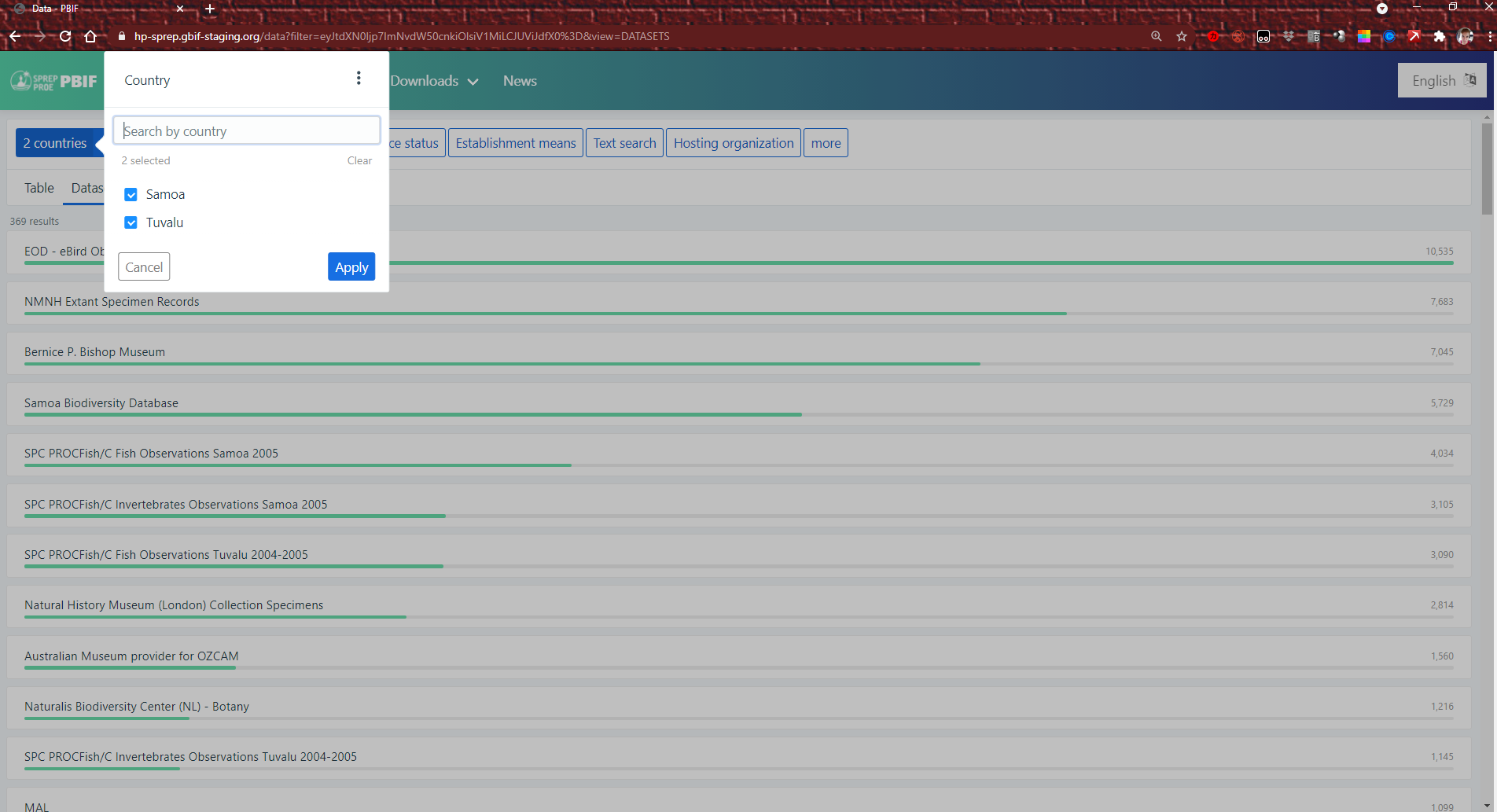
For those of us in the Pacific, a useful way to find related datasets from our region is to look at the datasets hosted by the SPREP Node. Here, we searched using “Secretariat of the Pacific Regional Environment Programme” as the Host Organisation. There were 52 results at the time, and this number is growing as you and your colleagues publish more data!
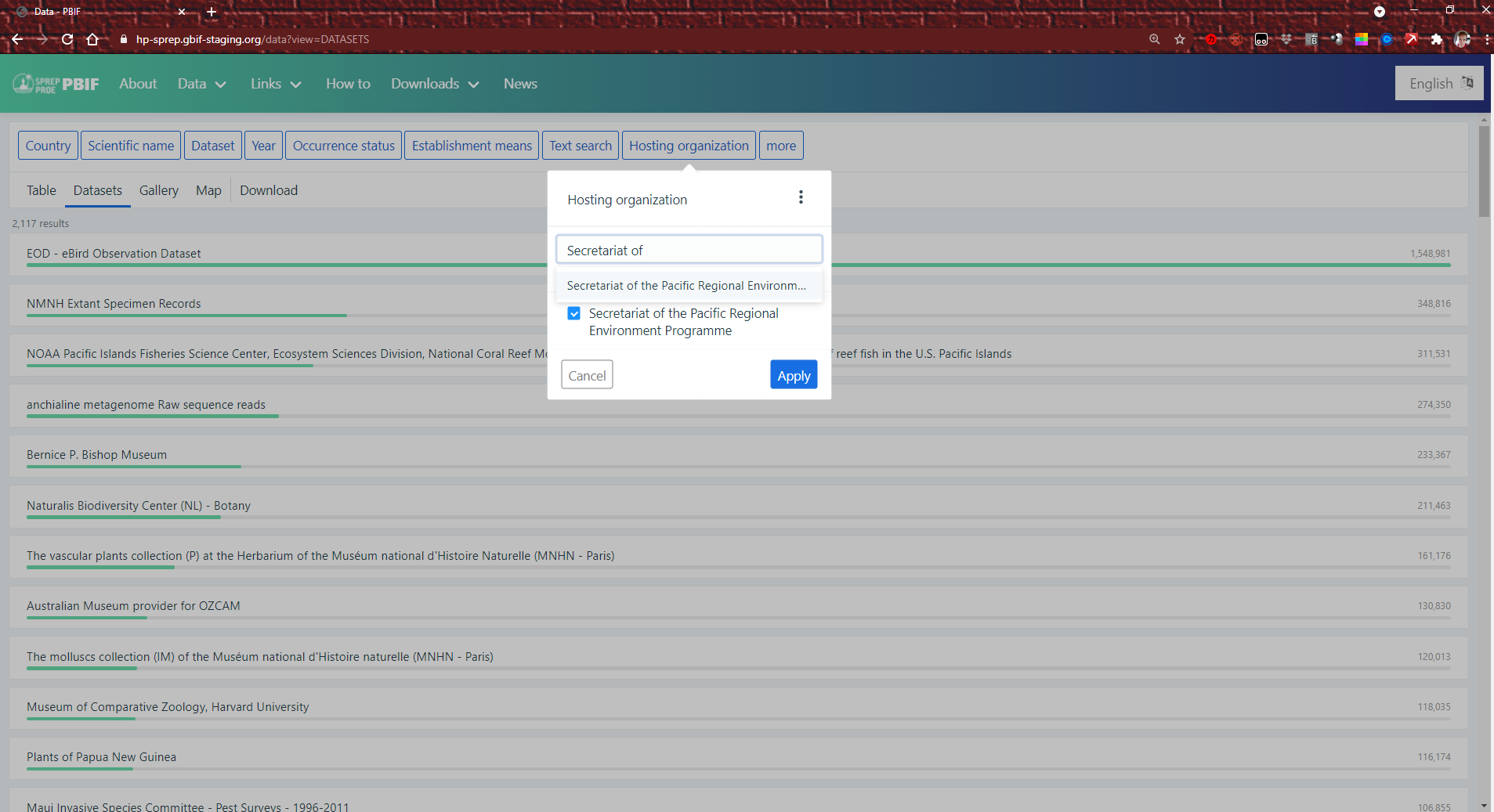
Click on a dataset name to find out more.
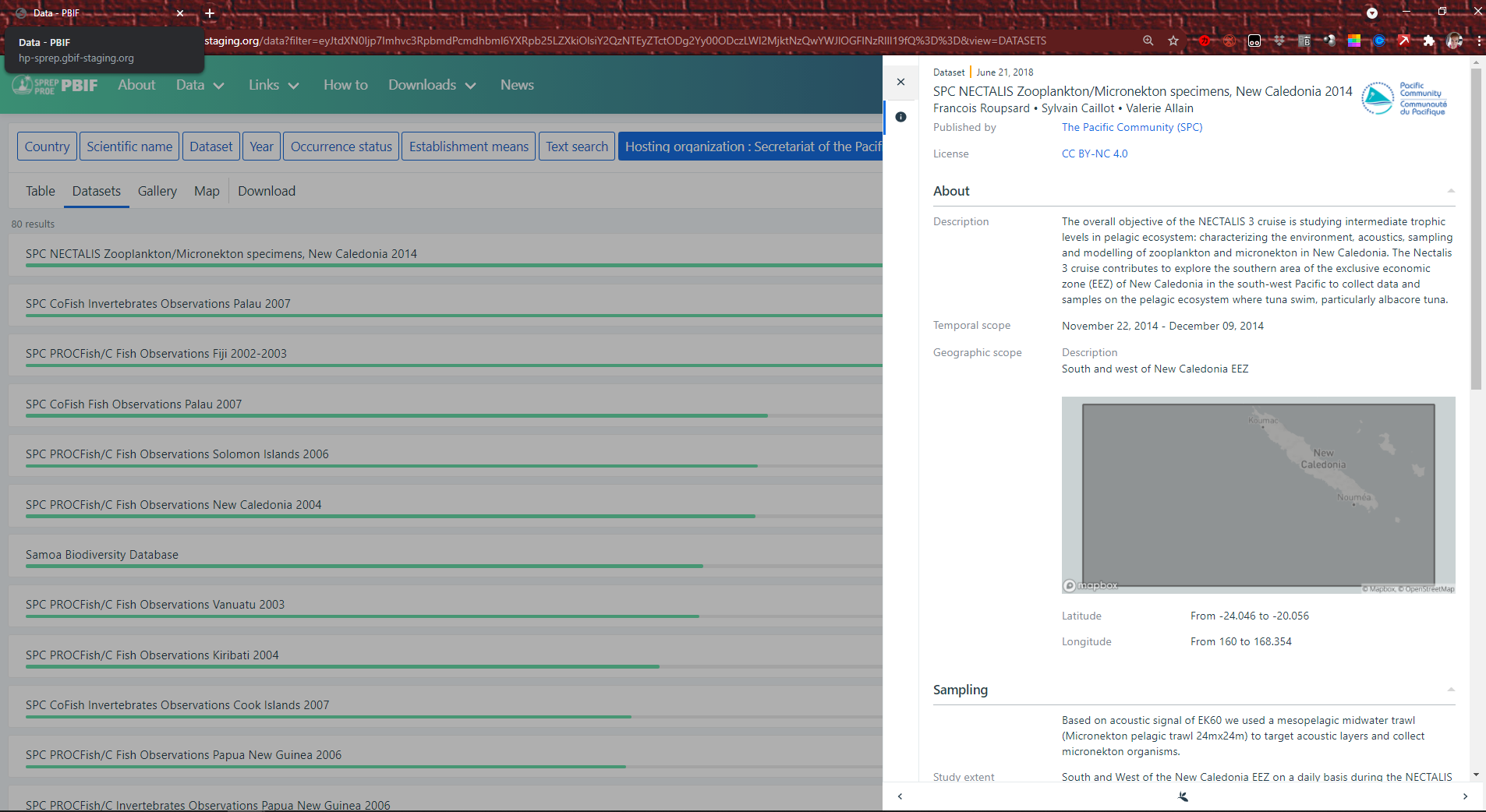
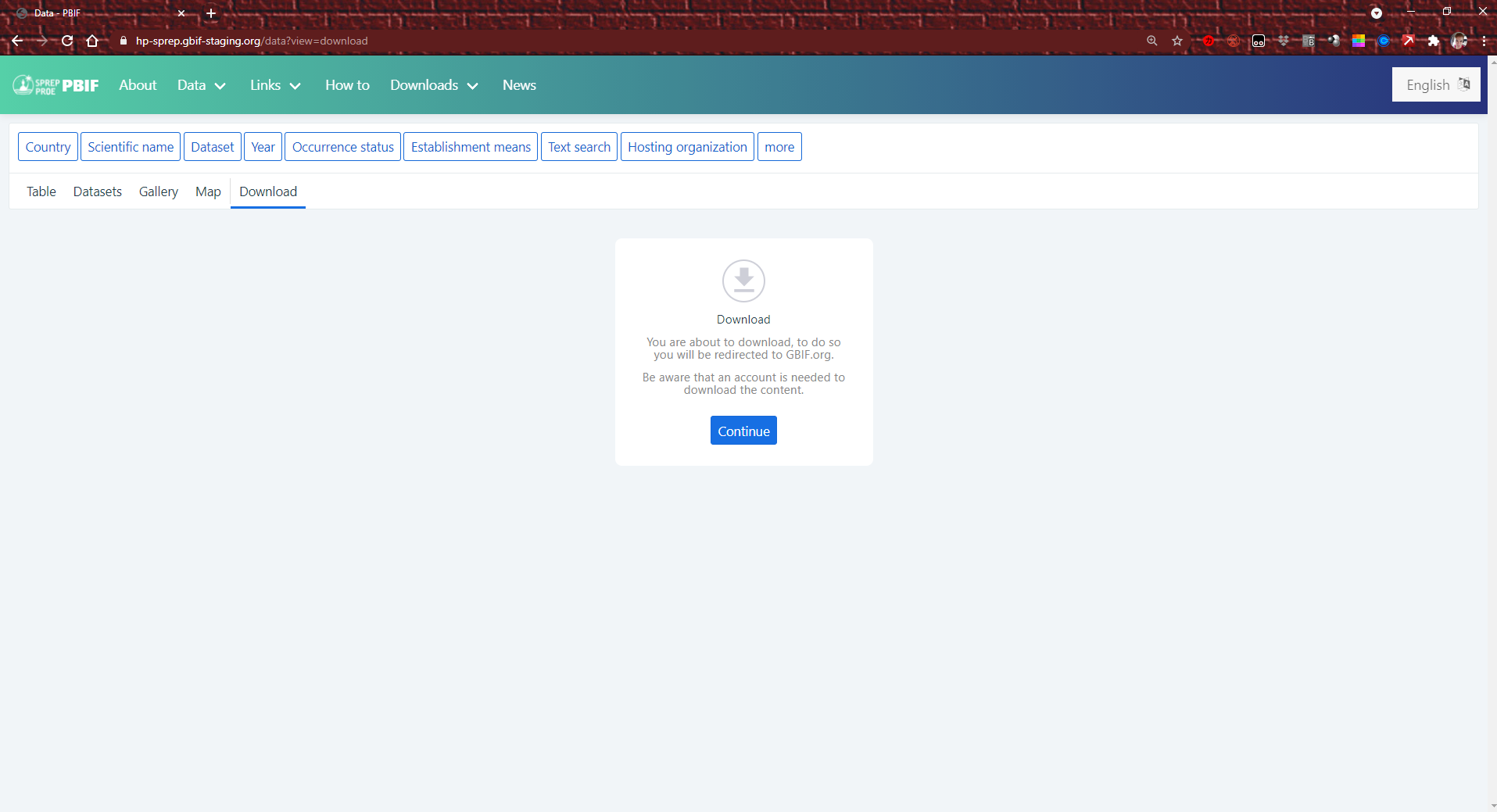
You can also download the whole dataset if you want, in
a few different formats. You will be redirected to www.gbif.org also please note an account is required to download the content.
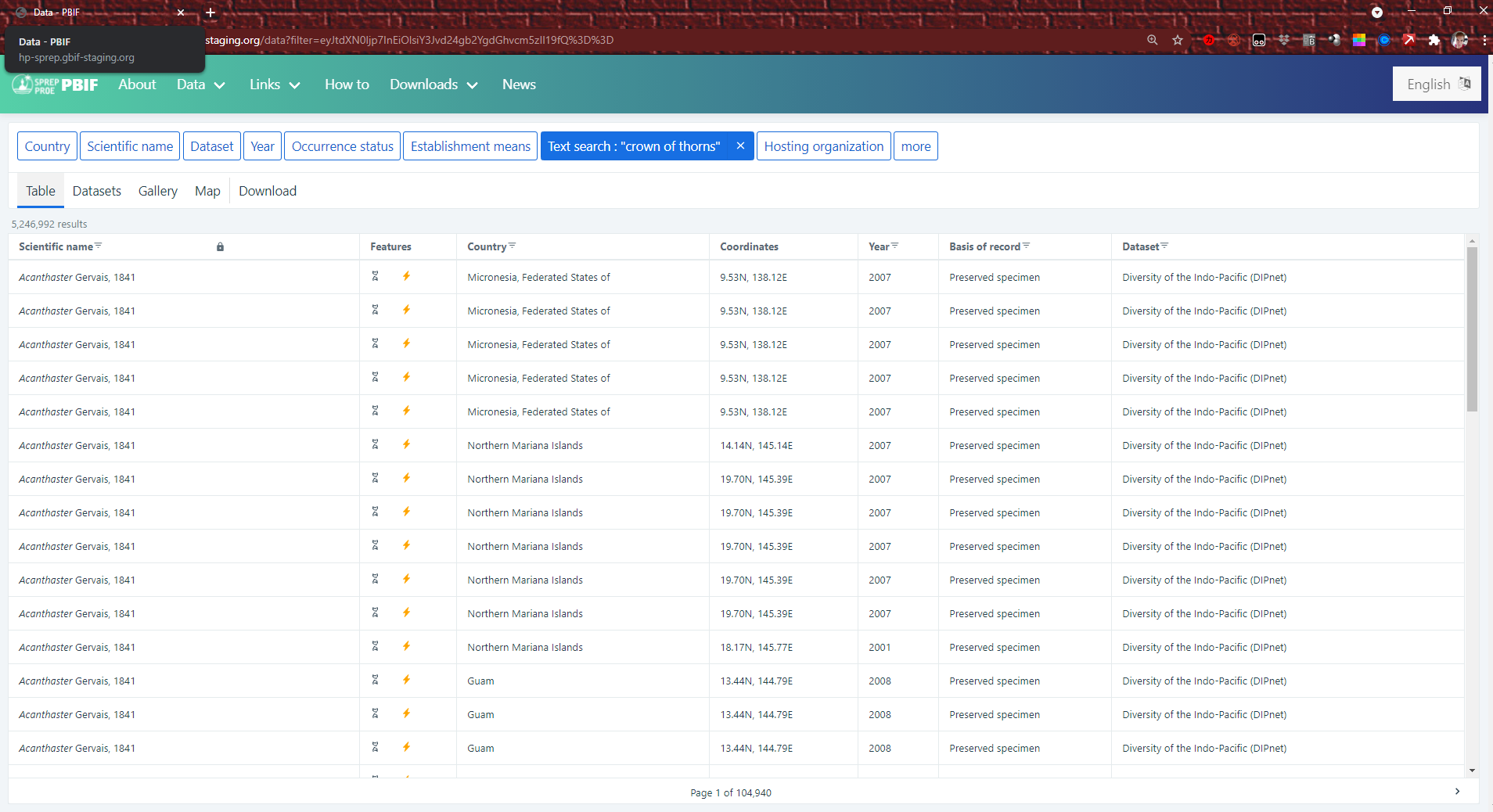
There are many ways to search, using filters, keywords, and more. One of the most common ways to search on the hosted portal is for a single species using the text search filter, and you can use either the scientific name (Latin name) or the common name (vernacular) to search. However, it is important to remember that the vernacular name might be different in different places, or the same name might be used for different species. For example, here is a search for “crown of thorns”. The search results include the sea star or starfish called “crown of thorns” but also include a plant, a fish, an insect, and more. For best results, you may want to search a few times using different names.
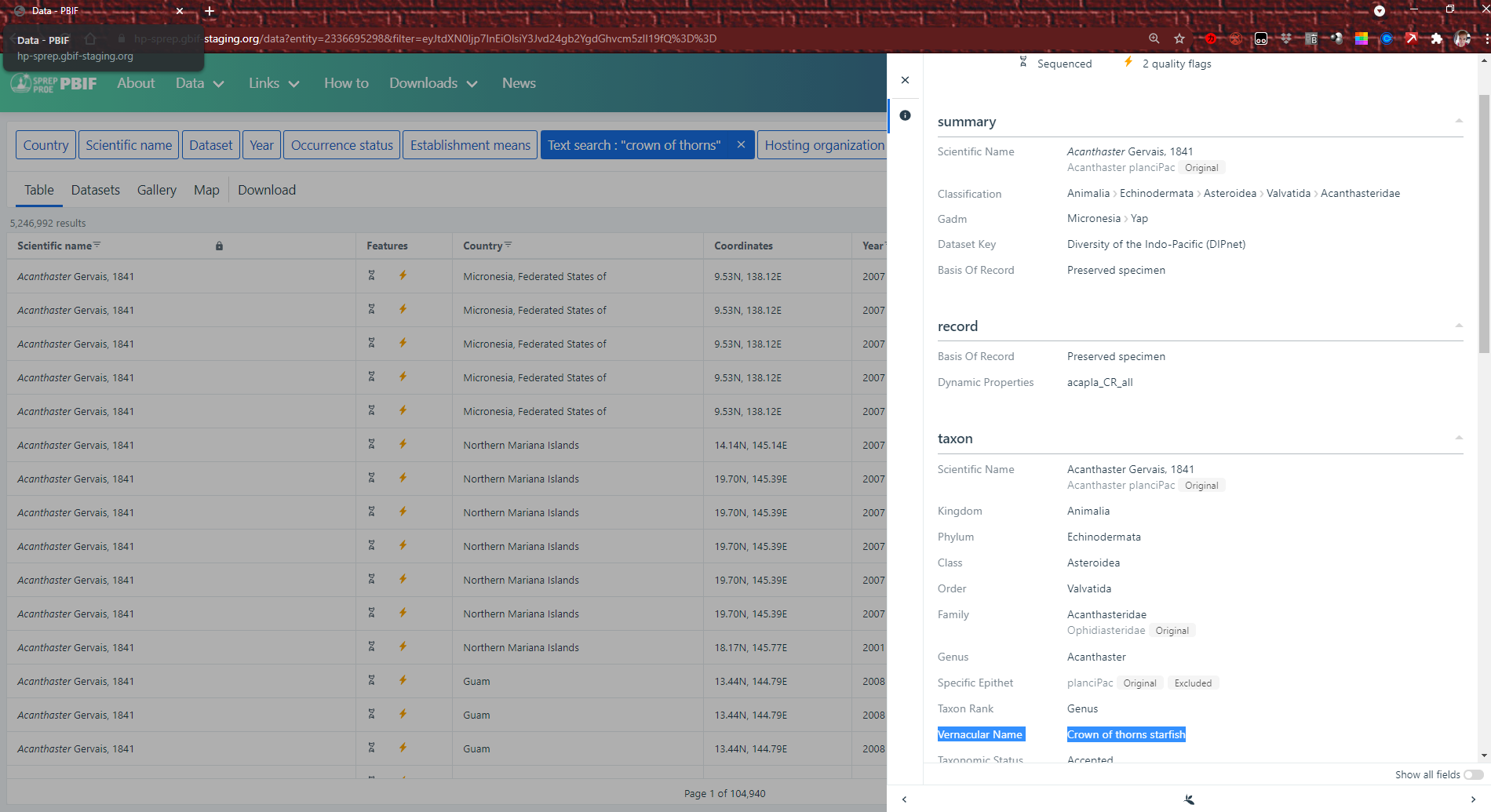
You can also choose to search “table” (occurrences, species, whole datasets, and more) by using the various filter options such as “country”, “scientific name” etc.
How do I publish data on GBIF?
First, you must register your organisation to GBIF, indicating that you’ll be using the SPREP
Integrated Publishing Tool (see below). After you have registered as a data publisher, you can
follow this step-by-step process to publish data on GBIF:
- Enter metadata for your dataset on the SPREP IPT.
- Have your source dataset Darwin Core ready (see below: “How do I prepare data for publishing”).
- Upload dataset to the IPT.
- Map your dataset to Darwin Core Terms, either as a Checklist Dataset or Occurrence Dataset (as appropriate for your data)
- Publish.
- Validate the dataset with the GBIF Data Validator, prior to registering the dataset www.gbif.org/tools/data-validator.
- Register the dataset with GBIF (first time-only).
- Receive feedback from GBIF and users.
- Update your source data. 10.Repeat from step 4. Note that the responsibility for maintaining datasets falls on the data publisher.
What if my data were published by another institution?
Datasets have unique Identifiers. If the dataset you want to share is already on GBIF, it is recommended that you don’t re-publish because GBIF will identify the dataset as redundant. A better solution, as a publisher, would be to link to that data already uploaded by the other institution. Remember, the publisher is not necessarily the only or original owner of the dataset, as defined in the metadata, they are just the one who did the work to publish it through GBIF. If another institution has already done that for you, go ahead and use it as an asset!
Pathways to data publishing
How do you decide what to publish? First, consider the type of species data that you most need and use. Sharing that data can help provide you a stable, recorded copy, and those data are also likely to be useful to others. Consider the goals of your active projects. In addition to new data, are there older data you would need to compare with any new findings? During project development, did someone have to dig up old files to try to identify the scope of the problem? Those data may be worth sharing. While data about endemic species or new areas are always interesting, it’s also true that data about species found in common areas are helpful to identify and plan for potential species invasions. Data that are already in tables or spreadsheets are ideal, but data in any format can be extracted and put into columns and rows. For example, you may have a report that verbally describes encounters with certain species in a particular area or areas. You can convert that into a dataset with the species name matched to the area, year of observation, and so on. You can decide whether it is occurrence data, checklist data, or sample event data. Each of these types requires different amounts and details of data. For more information, see http://rs.tdwg.org/dwc/terms/ and www.gbif.org/data-quality-requirements.
How do I register as a data publisher on GBIF?
The first step to sharing data with GBIF is to register, identifying your organisation as one that has quality data to share. Once you are registered, you can publish as many datasets as you like. The GBIF requirement for registration is that you have access to a node – in the Pacific islands, this means access to the SPREP node and Integrated Publishing Toolkit (IPT). You can register to become a publisher at any time, you do not need to have data ready. A publisher can also be registered to provide access to metadata, even if they are not ready to publish a dataset. A publisher may be a ministry, institute, organisation, and so on. For simplicity, we will use the term “institution” throughout these instructions.
-
Access the GBIF website at www.gbif.org. Click on Share tab – Become a Publisher and search for your institution to confirm whether or not your institution is already registered. If your institution is not registered, proceed to Step 2.
-
There is a data publisher agreement to consider. Agree to continue.
-
Fill in the details requested (e.g., name of institution, primary contact, website address, description of organisation, map location, etc.).
Remember to select that the endorsing node, as well as access to an IPT, will be through the SPREP node.
The site will ask whether you need help in publishing – the answer here is “No” because there is already assistance available to you via the SPREP Node Manager.
Contact Information: Provide your contact details within your institution. It is a good idea to also provide a general contact email for the institution (i.e. info@…………..) that will last even if a staff member leaves. The Technical Point of Contact will require the contact information of the Node Manager at SPREP. Note that if contact information changes, you may contact the GBIF Help Desk directly to update the contact information.
Provide a short description of your institution.
Select “No” to the question “Are you planning to install and run publishing software (such as the Integrated Publishing Toolkit – IPT) to publish your data directly to GBIF.org?”
-
Submit
-
A notification email will be sent to the contact person (Data Publisher) and a notification email will be sent to SPREP as the GBIF Participant Node.
-
Once the Participant Node has endorsed the institution for GBIF, the registration will be complete and now has a new publisher added to the GBIF site.
-
GBIF will send the contact person a password for the newly registered institution. This password will be required by the Node Manager to assist with registering new datasets to GBIF in the IPT.
Glossary of definitions
Data Publisher – any organisation / institution that shares data via GBIF.
Darwin Core Terms – Darwin Core Terms are a list of terms or fields that are of interest in the field of Biodiversity. A quick reference guide for Darwin Core terms can be found here: http://rs.tdwg.org/dwc/terms/, including definitions and examples of each term. A 2012 paper describing the Darwin Core Standard is here: https://doi.org/10.1371/journal.pone.0029715
Integrated Publishing Toolkit (IPT) – A software tool developed by GBIF to carry out dataset publishing, installed on a local or regional server. Participant Nodes often have one or more IPT instances for Data Publishers to use. The IPT we use in this instance is the SPREP IPT.
Metadata – data about the data, including the “who, what, where and when”. For example, if the piece of data that you want to publish is the occurrence of a species in a certain forest in May, your metadata may include who you are (name of your organisation, etc.), the purpose of data collection, methodology, range of sampling dates and geographic scope.
Node Manager – a person who manages the Participant Node. The Node Manager either is or directs the technical point of contact for data publishers.
OccurrenceID – An identifier for the Occurrence (as opposed to a particular digital record of the occurrence). In the absence of a persistent global unique identifier, construct one from a combination of identifiers in the record that will most closely make the occurrenceID globally unique.
Participant Node – a coordinating team (within a country or organisation) that works to establish and strengthen GBIF-related activities.
TaxonID – An identifier for the set of taxon information (data associated with the Taxon class). Maybe a global unique identifier or an identifier specific to the data set.
For More Information
Websites
| GBIF Homepage | www.gbif.org | Access, explore and publish biodiversity data |
| PBIF Homepage | pbif.sprep.org | Access and explore Pacific biodiversity data |
| IPT User Manual | https://github.com/gbif/ipt/wiki/IPT2ManualNotes.wiki | How-to guide to using Integrated Publishing Toolkit |
| Darwin Core Quick Reference | http://rs.tdwg.org/dwc/terms/ | Web page with definitions for Drawing Core terms |
| Copyrights for Data | http://vertnet.org/resources/dataliceningguide.html | Description of the choice of license for published data |